
Quick Answer:
The decision between a customer data platform (CDP), customer relationship management (CRM) system and data warehouse is a sequencing decision. Build the warehouse when metrics are breaking between teams. Start with a CRM when sales conversations still define product direction. Add a CDP or warehouse-native activation layer when clean data needs to reach campaigns without engineering overhead. Building all three at once guarantees none of them deliver value.
TL;DR
- Warehouse first. Build it when conflicting metrics appear across Google Analytics 4 (GA4), HubSpot and Salesforce and no one can agree on customer acquisition cost (CAC) or attribution.
- CRM first. Build it when the sales motion is still being defined and relationship data drives product decisions.
- CDP or reverse ETL third. Add it when the warehouse is stable and marketing needs to activate clean segments across campaign tools without writing SQL.
- Sequence matters more in 2026. AI workflows, warehouse-native CDPs and reverse ETL have raised the cost of building in the wrong order. Gartner predicts that 60% of AI projects lacking AI-ready data will be abandoned.
AI workflows and warehouse-native marketing tools have made the CDP versus warehouse versus CRM decision more urgent in 2026. If customer records, attribution logic and activation audiences are built in the wrong order, every campaign, dashboard and AI output inherits the same weak foundation. A 2025 report by the IBM Institute for Business Value found that 43% of chief operations officers identify data quality as their primary data priority, and over a quarter of organizations estimate they lose more than $5 million annually because of it.
They are asking which system should feed segmentation, lead routing, account-level reporting and AI workflows without creating another version of the truth.
When web analytics, CRM and campaign tools disagree, the instinct is still to buy another platform. The State of Martech 2026 report identifies data integration and customer data quality as the top operational challenges for marketing teams. The mistake is treating the CRM, CDP and warehouse as parallel purchases. The build order determines whether web events, lead routing, account-level reporting and campaign audiences use the same customer truth or create three separate versions of it.
Why the Darwin Flux Framework Changes This Decision
The CDP versus warehouse versus CRM question tends to get treated as a tool selection problem. Darwin Flux frames it as a sequencing problem with four stages that have to activate in order.
Surface captures the web and product signals first: GA4 events, Google Tag Manager (GTM) form fills, UTM-attributed lead source data and product usage events. Without clean surface data, every layer built on top of it inherits the same gaps.
Connections determine whether those signals move cleanly into HubSpot, Salesforce, the warehouse and activation tools without dropping context or splitting into separate versions of the same customer record.
Clarity appears when customer acquisition cost, web attribution, account-level reporting and lifecycle stage reconcile between marketing, sales and finance. This is the warehouse layer: the place where metric definitions become shared rather than team-specific.
Momentum starts only when that foundation is stable. Automation, AI segmentation, reverse extract, transform and load (ETL) workflows and revenue-triggered campaigns depend on the data being clean, connected and consistently defined before they run.
In Flux terms, the practical decision is which stage is broken now and which platform fixes it without adding new fragmentation.
What Role Each Platform Actually Plays in a GTM Stack
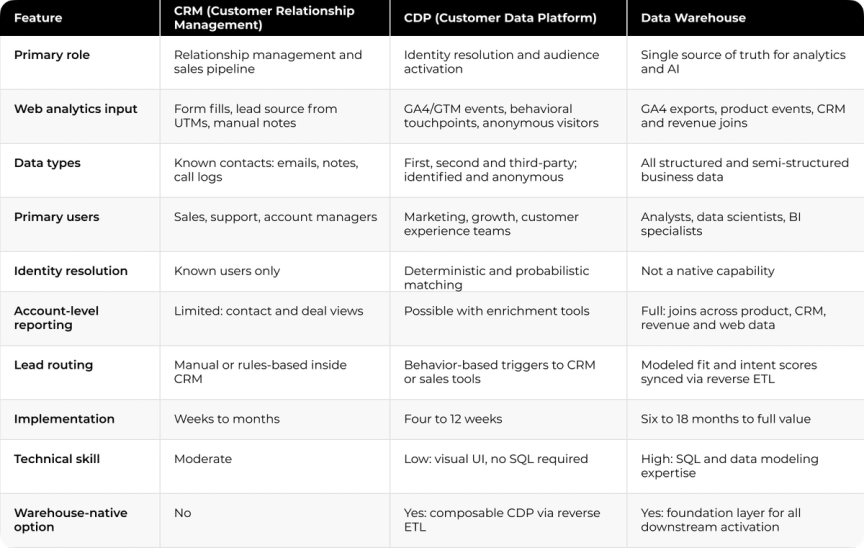
A CRM records what your team did with each contact. A CDP captures what customers did on their own. A data warehouse is where GA4 events, CRM records and product usage data join into one reporting layer. Each platform owns a different part of the customer record. Without all three connected in the right order, each one produces a different version of the same customer.
CRM: The Operating Layer for Known Relationships
A customer relationship management (CRM) system records every interaction between your team and a known contact. Sales calls, support tickets, email exchanges, pipeline stages and deal notes flow into a single system so anyone on the team can see the full relationship history without asking.
For web analytics purposes, the CRM is where form fills land, UTM-attributed lead source gets recorded and sales context around each inbound lead gets captured. It is the layer where website signals become pipeline records. A sales rep logs a call. A support agent updates a ticket. A marketer records a campaign response. The data reflects what your team did with the lead after the web touchpoint.
For teams where the sales motion still shapes product direction, the CRM record of human conversations is the most valuable data asset available. Identity resolution and audience activation add overhead before the product motion is clear.
CDP: The Activation Layer for Behavioral Data
A customer data platform (CDP) collects customer data from every digital touchpoint automatically: websites, mobile apps, email interactions, offline transactions. It builds continuous profiles without requiring manual entry, resolves identity across anonymous and known users, and pushes segmented audiences to the channels where campaigns run.
The capability that separates CDPs from other platforms is identity resolution. When someone visits your site anonymously, signs up through your app, then contacts support, a CDP connects those interactions into one profile using deterministic matching on email addresses and customer IDs, and probabilistic matching on IP addresses and behavioral patterns.
In 2026, many mid-market SaaS teams are choosing a warehouse-native or composable CDP model over a standalone CDP database. According to the January 2026 CDP Institute Industry Update, composable and warehouse-native vendors grew employment by 7.8%, nearly six times the 1.3% industry average, signaling a clear shift in where CDP adoption is concentrating. That model uses the cloud warehouse as the customer data foundation, then uses reverse ETL tools to activate modeled segments in campaign tools, ad platforms and CRMs.
"The CDP's job is not to be the system of record. It is to make data from the system of record usable by the people running campaigns." David Raab, Founder, CDP Institute
Data Warehouse: The Foundation Layer for Analytics and AI
A data warehouse pulls processed data from transactional systems, databases, CRM platforms and other sources into centralized storage built for complex queries. It handles all structured and semi-structured data in the business: billing records, claims data, product usage logs, employee records, transaction history.
For web analytics, the warehouse is where GA4 event exports, GTM-captured form fills, product usage events and CRM attribution data finally join. Without that join layer, web traffic numbers live in GA4, pipeline attribution lives in HubSpot, and revenue data lives in Stripe or Salesforce. The warehouse creates the shared definition layer that makes account-level reporting and cross-channel attribution possible.
Common warehouse platforms for mid-market SaaS include Snowflake, BigQuery and Databricks. Databricks is increasingly chosen by teams that need a unified lakehouse for both analytics and AI model training, since it handles unstructured data and machine learning workloads alongside standard SQL analytics.
CDP vs CRM vs Data Warehouse: Direct Comparison
The table below captures the operational and web analytics differences that affect build decisions.
Which Platform to Build First: A Decision Framework for SaaS Teams
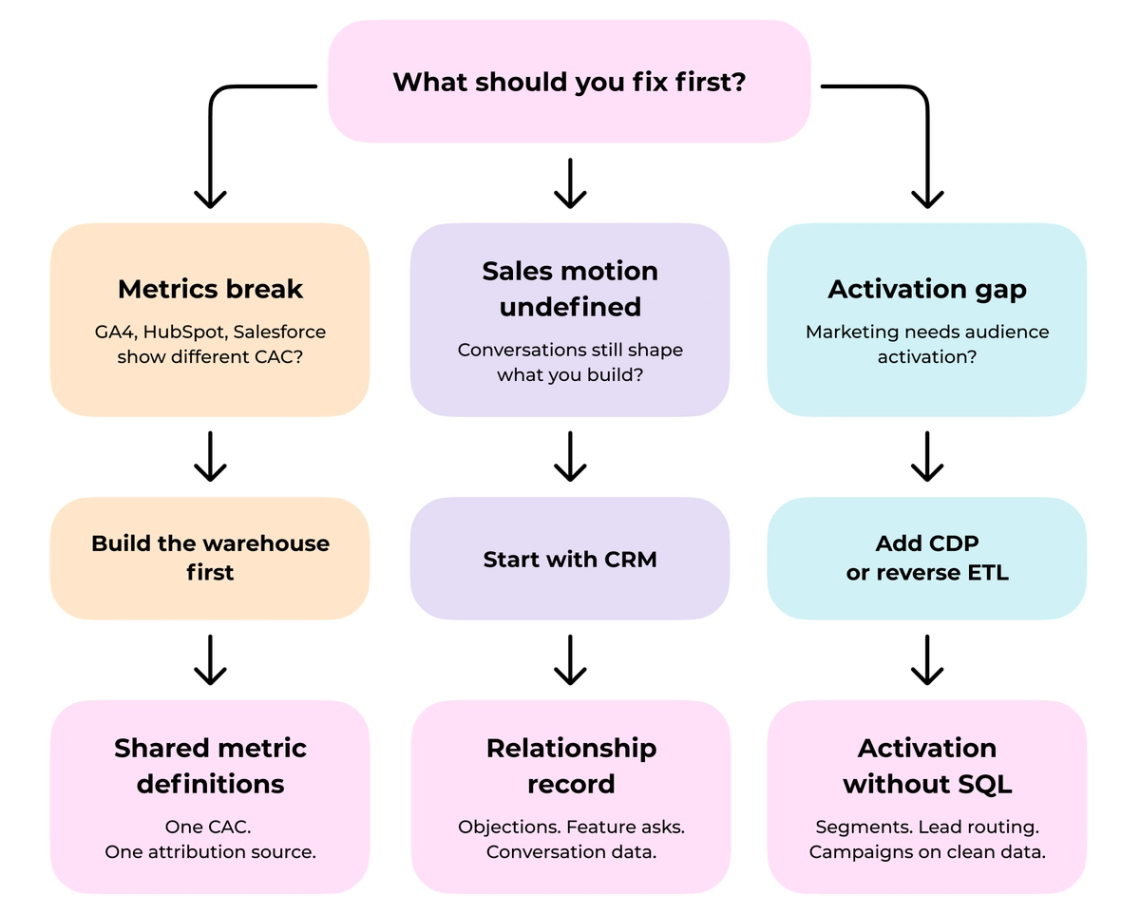
Build the Warehouse When Reporting Is Breaking
The signal is specific: GA4 reports one number, HubSpot reports another and Salesforce shows a third. CAC differs between dashboards and no one can explain why. Analysts spend hours downloading CSV files when they should be running queries. Marketing cannot see downstream revenue. Product cannot connect feature usage to acquisition channels.
This is the Connections layer failing. Every team defines metrics independently because there is no single layer where those definitions live. Web attribution breaks first: the lead source captured in GA4 does not match what HubSpot recorded, which does not match what the CRM shows as the deal source.
A warehouse resolves this by centralizing data from all sources and establishing one definition of each metric. Finance and marketing agree on CAC because they query the same table. Product and acquisition agree on attribution because the joins happen in one place. Account-level reporting becomes possible because anonymous web visits, product usage events and CRM records finally connect.
The foundation stack for this stage: an ingestion tool such as Fivetran or Airbyte, a cloud warehouse such as BigQuery, Snowflake or Databricks, a transformation layer such as dbt, and a business intelligence (BI) tool such as Metabase. This combination handles data collection, centralized storage, modeling and reporting without requiring enterprise-scale infrastructure.
Start With CRM When Sales Conversations Still Define Product Direction
Before a product has found its market, the most valuable data is qualitative. What objections kill deals. What features customers say they need. Why someone chose a competitor. That information lives in sales conversations, not behavioral event streams.
A CRM captures those conversations. Every prospect interaction, every feature request, every objection gets recorded so the team can see patterns. GA4 can tell you traffic volume; the CRM tells you what the traffic said. At this stage, that record is more useful than an analytics pipeline.
Add CDP or Warehouse-Native Activation When Activation Gaps Appear
The signal: the warehouse is running, data quality is stable, but marketing cannot act on it without engineering support. Segment creation requires a SQL query and a support ticket. Campaign audiences get built manually from exports. Lead routing rules cannot consume account-level intent signals because they live in the warehouse and nothing moves them into the CRM.
This is where Momentum begins. A warehouse-native activation layer resolves the gap. Hightouch is one example of how this works in practice. Hightouch and Census push modeled data from the warehouse into HubSpot, Salesforce, ad platforms and support tools without engineering involvement in each sync. According to a 2025 survey by dbt Labs and Census, organizations using reverse ETL report a 41% reduction in time-to-action on data insights and a 2.8x improvement in marketing campaign targeting precision.
A clean account score can route leads to the correct sales motion, update lifecycle stage in HubSpot and trigger audience membership in paid channels simultaneously.
For teams evaluating Segment as a standalone CDP, the 2026 question is whether the activation capabilities are worth maintaining a separate customer data database, or whether a composable model using the existing warehouse delivers the same outcomes with less duplication. CDP.com's 2026 vendor comparison covers how leading platforms have shifted toward warehouse-native models.
"The teams that get the most out of a CDP are the ones who already know what data they need and where it needs to go. Without that clarity, a CDP becomes another data silo with a better UI." Kamil Rejent, CEO, Survicate
Team Size and Technical Readiness as Decision Inputs
A 10-person team with one analyst and no dedicated engineering does not need a warehouse that takes 18 months to deliver value. A 200-person team with five analysts and a data engineering function does not need a CDP before the warehouse is stable.
Platform selection without accounting for who will run it creates adoption failure. Enterprise tools assume dedicated administrators, approval workflows and integration specialists. When those roles do not exist, the overhead exceeds the value.
How to Connect the Stack Without Creating New Silos
The warehouse stores data. Reverse ETL moves it back into CRM, ad platforms and support tools. Both depend on what enters the stack first: web and product signals captured through GA4 and GTM. The sections below cover how each connection point works, starting with event capture and ending with account-level reporting.
Reverse ETL as the Activation Bridge
Reverse ETL changes the direction of operational data movement: modeled warehouse data is pushed back into the tools where sales, marketing and support teams work. CDP.com outlines where reverse ETL and CDP each fit in the activation stack.
Data flows from the warehouse into CRMs, ad platforms, support desks and product surfaces. Sales sees enriched account scores alongside contact records. Marketing runs campaigns on warehouse-defined segments without exporting CSV files.
Specific activation use cases that justify the investment: lead routing decisions based on modeled fit and intent scores, account-level audience membership synced to LinkedIn and Google Ads, lifecycle stage updates triggered by product usage thresholds, and churn signals pushed to support queues before renewal conversations. Teams that implement warehouse-native activation report measurable improvements in campaign targeting and a drop in manual data preparation work per reporting cycle.
Web Analytics as the Surface Layer
GA4 and GTM events are the starting point for the entire stack. A form fill captured by GTM becomes a lead in the CRM. A product usage event tracked in GA4 becomes a behavioral signal in the warehouse. A page visit attributed to a paid campaign becomes part of the multi-touch attribution model that finance and marketing both query.
When GA4 configuration is inconsistent, when GTM tags fire incorrectly, or when form fills do not carry UTM parameters into the CRM, the entire downstream stack inherits the error. Attribution breaks. Account-level reporting shows gaps. AI workflows train on incomplete signals.
This is the Surface layer. Web and product signals need to be captured correctly before they can support any downstream reporting, segmentation or activation.
Account-Level Reporting as the Clarity Signal
For business-to-business (B2B) SaaS, individual contact-level data is rarely sufficient for marketing and revenue decisions. The question is what is happening at the account level: which companies are engaging with which content, how product usage maps to renewal risk, which acquisition channels bring accounts that expand.
Account-level reporting requires the warehouse. It needs joins between web visit data, product usage events, CRM account records and revenue data. No single platform holds all four. When the warehouse is the canonical layer, account-level views become a standard report. Without it, account-level data gets assembled manually in spreadsheets that contradict each other by the time they reach the same meeting.
What Mid-Market SaaS Teams Get Wrong
Five mistakes appear in the same order across mid-market SaaS teams. Each one delays value from the platform that was just purchased.
Building All Three Simultaneously
When a team implements a CRM, CDP and warehouse at the same time, engineering attention splits between three projects with different stakeholders, different success metrics and different integration requirements. All three systems end up partially configured, loosely integrated and underutilized.
Each system needs a clear owner, a defined use case and an adoption plan. Three simultaneous implementations compete for all three. Six months in, the team has three tools that do not talk to each other and a data quality problem that is worse than before.
Choosing Enterprise Tools Before the Team Can Run Them
Snowflake and Salesforce Marketing Cloud are built for teams with dedicated administrators, approval workflows and integration specialists. A 15-person team at $3M in annual recurring revenue (ARR) does not have those roles. The overhead of maintaining an enterprise platform without the supporting team structure exceeds the value it delivers.
Buying CDP Before Warehouse Data Is Clean
A CDP activates data. If the underlying data is inconsistent, the activation produces inconsistent results. Campaigns go to the wrong segments. Attribution numbers do not match. Personalization triggers on bad signals.
The warehouse has to come first. Data quality, metric definitions and transformation logic need to be stable before activation tools can do their job. A CDP purchased to solve a data quality problem adds a layer without fixing the root cause. According to Gartner, poor data quality costs organizations an average of $12.9 million per year.
Ignoring GA4 and GTM Configuration Until It Is Too Late
Web analytics configuration cannot be revisited later once the stack is built on top of it. When GA4 events are not mapped correctly, when GTM fires on the wrong conditions, or when UTM parameters drop before they reach the CRM, every downstream system builds on broken inputs.
Attribution models are wrong. Account-level visit data is incomplete. AI workflows trained on event data inherit every misconfigured tag. Fixing web analytics after the warehouse and activation layer are built means reconciling months of corrupted historical data.
Building in Isolation Instead of Designing for Connection
Each platform gets selected and implemented by a different team. Sales owns CRM. Marketing owns CDP. Analytics owns the warehouse. None are designed to connect from the start. The result is three platforms with three definitions of the same customer.
Connection has to be designed into the stack from the beginning. That means agreeing on a canonical customer identifier, defining shared metric logic before building dashboards, establishing data ownership rules before onboarding the first tool, and deciding upfront how GA4 events, CRM records and product usage data will join in the warehouse.
How Darwin Sequences Customer Data Infrastructure for Mid-Market SaaS
Most data stack decisions fail at the sequencing stage, not the technology stage. Teams select capable platforms but implement them in the wrong order, configure them in isolation, and end up with three systems that each tell a different story about the same customer.
Darwin works with VP Marketing and Marketing Ops leaders at mid-market SaaS companies by starting with the stage that is broken. If web and product signals are not captured correctly, that is a Surface problem and GA4/GTM configuration comes first. If data is captured but does not connect across tools, that is a Connections problem and warehouse architecture comes next. If data is connected but teams still disagree on metrics, that is a Clarity problem and shared definitions and BI layer come before any activation work. If all three are stable, Momentum starts: reverse ETL, AI segmentation and automated campaign logic that runs on a clean, connected foundation.
For one client, Darwin consolidated five disconnected data sources into a single warehouse layer, unified CAC and LTV metric definitions between marketing and finance, and reduced manual reporting time by 70%. Segmentation accuracy improved from 70% to 90% because campaigns ran on warehouse data, not platform exports.
- Surface first. Validate GA4/GTM event capture, UTM consistency and form fill attribution before building anything downstream.
- Connections second. Design warehouse architecture, ingestion pipelines and CRM data flow so every team queries the same source.
- Clarity third. Establish shared metric definitions, build the BI layer and confirm that CAC, attribution and lifecycle stage reconcile across functions.
- Momentum last. Implement reverse ETL, activation layers and AI workflows once the foundation can support them without propagating errors.
If one of those stages is broken, adding the next one makes the problem harder to find.
FAQ
Q1. Can a CDP replace a CRM?
A CDP and a CRM serve different functions. A CDP collects behavioral data from digital touchpoints and activates it for marketing. A CRM holds relationship data entered by sales and support teams. The CRM is the record of what your team did. The CDP is the record of what the customer did independently. Both are needed; neither replaces the other.
Q2. When does it make sense to build the warehouse before adding a CRM?
When reporting inconsistency is already visible. If GA4, HubSpot and Salesforce all show different CAC numbers, or analysts spend time reconciling spreadsheets when they should be running analysis, the warehouse resolves the root problem. A CRM added on top of a clean warehouse delivers more value than one added before any shared data foundation exists.
Q3. What is a warehouse-native CDP and when does a SaaS team need one?
A warehouse-native CDP uses the cloud warehouse as the customer data foundation and activates modeled segments into campaign tools via reverse ETL. It avoids duplicating customer data into a separate CDP database. Teams choose this model when the warehouse is already the canonical data layer. Hightouch and Census are the primary tools in this category.
Q4. How does GA4 configuration affect the warehouse and activation layer?
GA4 events are the starting input for web attribution, product analytics and account-level reporting. When GA4 is misconfigured, every downstream system inherits the error. Attribution models break. Warehouse joins produce incomplete account views. AI workflows train on bad signals. GA4 and GTM configuration should be validated before the warehouse ingestion layer is built.
Q5. How do we know when the data stack is ready for AI workflows?
When the warehouse is the canonical source for all reporting, metric definitions are agreed on between teams, web events are captured consistently, and CRM and activation tools sync from warehouse data instead of keeping independent versions of the same customer record. Gartner predicts that 60% of AI projects lacking AI-ready data will be abandoned. The foundation has to come before the model.


